We are 600 million Spanish-speaking people. We launched the #Somos600M Project because we need the richness of our languages to be represented in AI systems.
Despite being 7.5% of the world’s population, we do not have an open instruction corpus that allows us to train native LLMs, nor standardized methods to evaluate them. The #Somos600M Project aims to create these two resources, essential for the development of AI in our languages.
The best part? We have several initiatives to achieve these goals and… EVERYONE can contribute! 🎉

🚀 Our Goals
We are an international community of Spanish-speaking people passionate about NLP. Our mission is to achieve fair representation of Spanish and co-official languages in the digital world through the creation of open resources.
In the Spanish-speaking community, we do not have our own LLMs adapted to follow instructions. This adaptation improves the versatility of models, which is important for AI alignment and conversational and RAG applications. Therefore, in this project we have set two initial high-impact goals:
- 🌎 Create the largest high-quality and diverse instruction corpus, including various NLP tasks, representing the different varieties of Spanish and co-official languages, and allowing us to train native and inclusive models.
- ✅ Create the first open leaderboard for generative LLMs that allows us to standardize how to evaluate and compare different models in Spanish and co-official languages, offering public and impartial results.
💡 Initiatives
Instruction Generation
💻 [COMPLETED] Hackathon: Create a dataset and train your own LLM
By joining this hackathon you will have the opportunity to collaborate in the creation of high-quality and inclusive LLMs in your language. Apply your knowledge to overcome the challenges of each stage of your LLM development: corpus creation, training, and evaluation.
Each participating team (1-5 people) will generate an instruction corpus, train their LLM, and create a demo to share their great work with the community.
At SomosNLP we want to encourage you to participate regardless of your current knowledge. We will organize practical workshops and mentoring sessions so that both research institute groups and undergraduate student groups can participate — all projects count!
Standardize Evaluations of Our LMs
🔍 Validate English to Spanish translations
Do you speak Spanish and English? Regardless of whether you know about AI, you can help us create the first public ranking of LLMs in Spanish 🔥
As a community, we are going to validate the translations made by the University of Oregon of the datasets used in the famous Hugging Face Open LLM Leaderboard. Thanks to the support of Argilla and Hugging Face, contributing is very easy:
- Create an account on Hugging Face
- Enter the annotation space
- Validate the translation of a paragraph from English to Spanish
- Repeat step 3 as many times as you want and watch yourself climb in the contributions ranking
- Your name will appear as part of the team that created the datasets
Extra. Additionally, there will be prizes to choose from among credits to train LLMs and a discount on a writing course for the people who have contributed the most quality corrections.
✨ Collaborate or donate evaluation corpora in Spanish
We are going to create the first open leaderboard for generative LLMs in Spanish.
We are looking for both collaborations with research groups and donations of evaluation corpora in Spanish covering diverse tasks and topics. If you are interested in collaborating on the creation of this leaderboard, contact us at info@somosnlp.org. If you are interested in having your corpus included, donate your corpus. We look forward to hearing from you!
✨ Collaborate or donate corpora in languages of LATAM and Spain
We are going to create a multilingual leaderboard for languages of LATAM and Spain.
We are looking for both collaborations with research groups and donations of evaluation corpora in the different languages of Spanish-speaking countries. If your research group has resources (both open and private that you would like to donate), let us know — it will be a pleasure to leverage your great work!
Contact us at info@somosnlp.org or find out how to donate your corpus. We look forward to hearing from you!
Corpus Collection Campaign
📚 Donate a dataset
As you know, the key to AI lies in the data. As you have seen, the #Somos600M initiative is primarily focused on the creation and collection of datasets. So whether you have a wonderful corpus or a pile of documents, you can surely contribute!
Free Training for All Levels
💡 Attend expert talks
At SomosNLP we believe that training yourself is also a way to contribute to the future of NLP in our languages. During the Tuesdays of March, we organized various keynotes delivered by professionals in the field of Natural Language Processing. All our events are free and open to everyone.
🔊 Propose a talk
We invite people from academia or industry, experts and enthusiasts in the field of AI and particularly NLP, to share their knowledge and advances. Read the suggested topics and send us your proposal!
🧑🏫 Offer mentorship
Share your experience and knowledge by supporting the community in creating quality datasets and training LLMs responsibly. Outside of hackathon periods, you can host an AMA (Ask Me Anything) session on the topic of your choice. Think about your strengths and offer mentorship!
Joining Forces with Aligned Initiatives
🤩 Tell us about your project
Contact us if you are researching NLP in Spanish, co-official languages, or indigenous languages of LATAM. We want to give visibility to all initiatives aligned with our mission and we would love to add yours to the list.
Send us an email at info@somosnlp.org or contribute directly to the Space — it will be a pleasure to meet you!
🤗 Join the team
You can collaborate by creating content, support resources (e.g., tutorials), writing articles, or researching AI in Spanish.
🙌 Sponsor this wonderful project
SomosNLP is a non-profit community. We seek donations, prizes, and visibility to achieve our ambitious goals and create impact in the Spanish-speaking world. All help is welcome — discover how you can support our mission by offering visibility, vouchers, and donations. We count on you!
🚀 Progress
Initial Situation
Instruction corpora originally created in our languages:
- MentorCA, created by AINA and ILENIA (Catalan, 10k)
- MentorES, created by AINA and ILENIA (Spanish, 10k)
- AYA Dataset ES, created by CohereForAI (Spanish, 4k)
Leaderboards for discriminative models with tasks originally created in our languages:
If you are working on a similar project or know of more resources, let us know :)
Current Situation
The teams from the SomosNLP 2024 #Somos600M Hackathon created 18 instruction corpora:
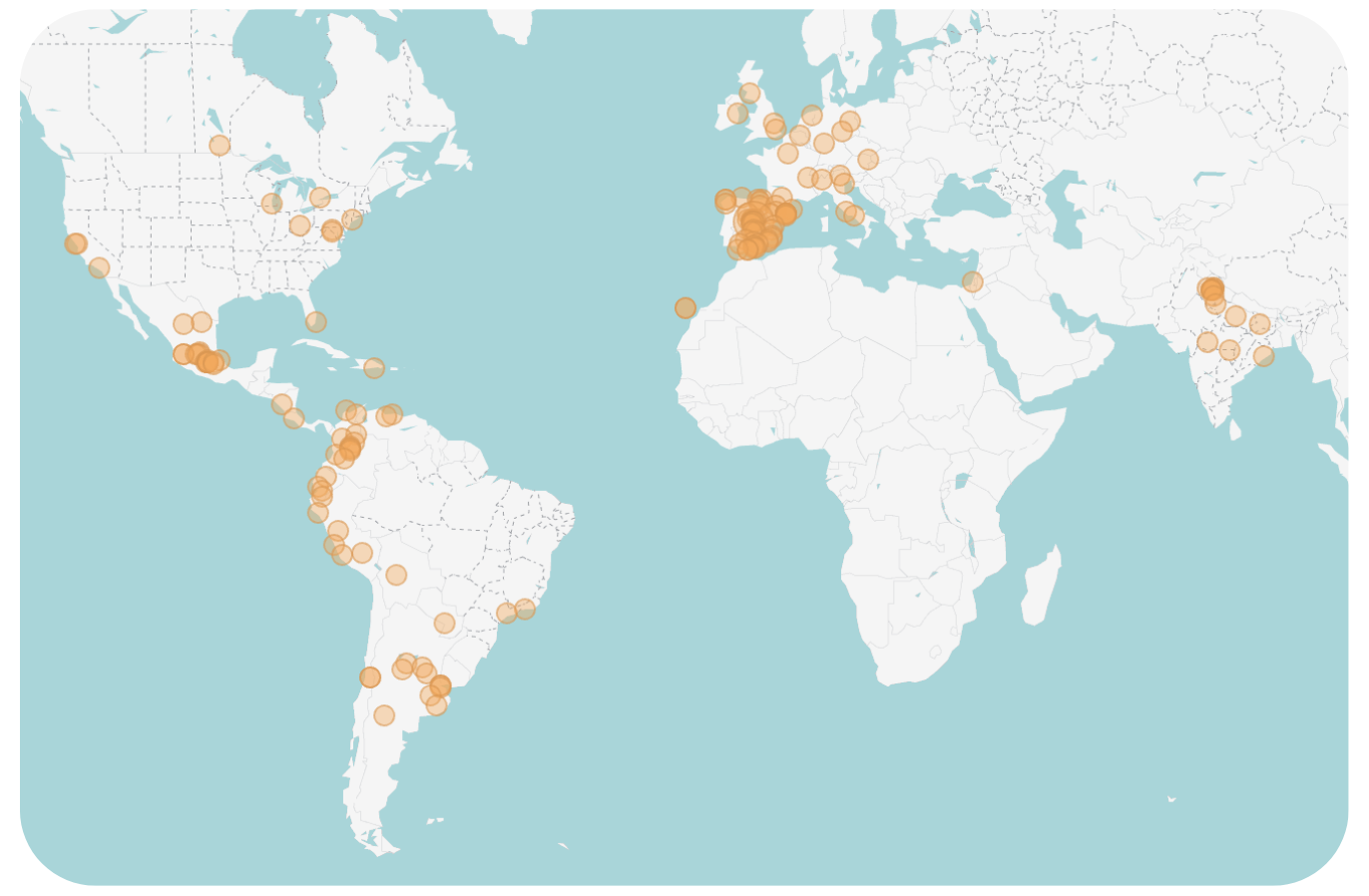
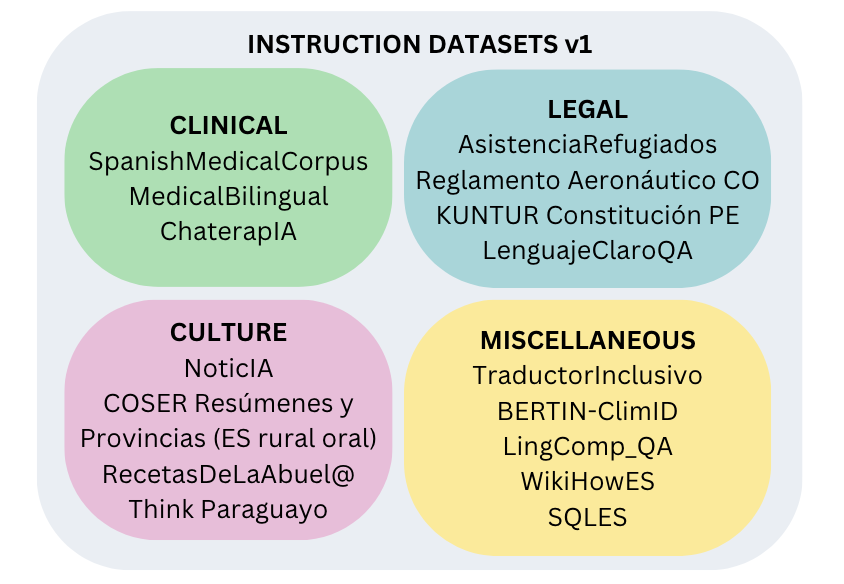
Thanks to donations from 5 research groups, on July 1st we will launch the first version of the leaderboard:
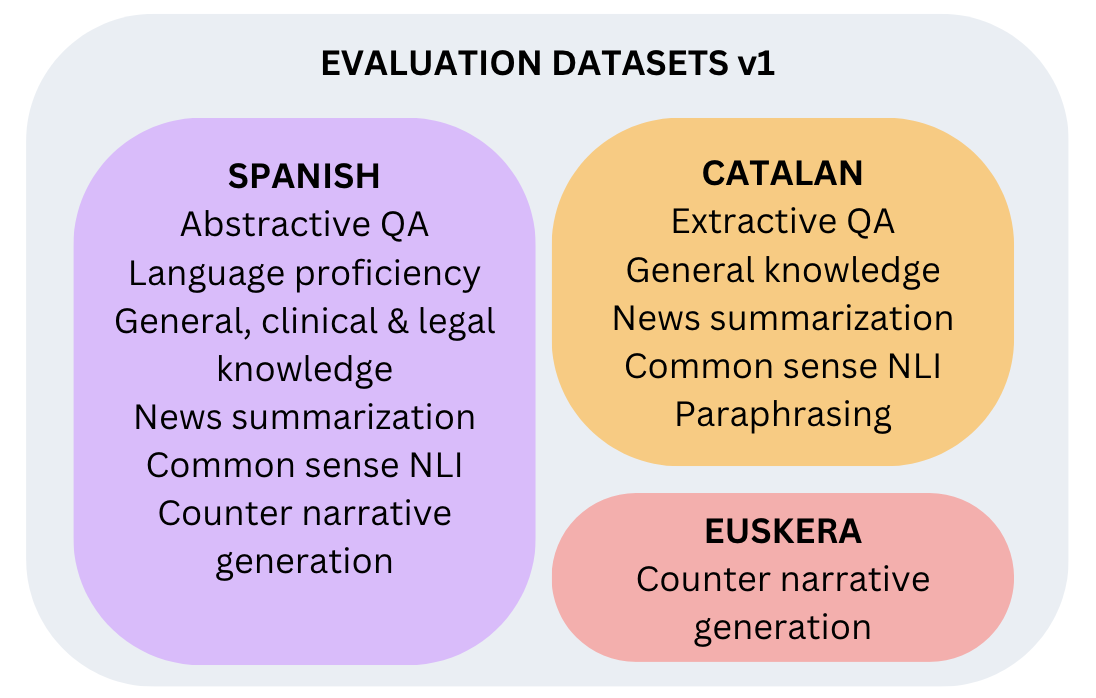
Next Steps
- Publish the v1 of the leaderboard on July 1st
- Add more tasks and languages to the leaderboard
- Scale the corpus collection campaign
- Organize hackathons focused on specific topics and languages
👏 Acknowledgments
Thank you so much for your time and for supporting us so that our initiative can reach further. Let’s make NLP more inclusive!
Gold Sponsorships


Corpus Sponsorships





Gold Sponsorships for the #Somos600M Hackathon




Community Sponsorships









🤗 Connect!
We are looking for collaborations with research groups from LATAM, the Caribbean, and Spain — contact us!
If you would like to join the community, attend our events, and participate in our initiatives, here are different ways to connect:
- Join the community on Discord (we are already more than 1900!)
- Follow us on Twitter and LinkedIn
- Subscribe to our YouTube channel
- Save events from the Google calendar